表紙
はじめに
Ⅰ PowerFolderの概要
Ⅱ PowerFolderのデータ管理
Ⅲ PowerFolderの使い方
はじめに
Ⅰ PowerFolderの概要
Ⅱ PowerFolderのデータ管理
Ⅲ PowerFolderの使い方
Ⅲ-1 画面構成
Ⅲ-2 表の扱い方
Ⅲ-3 フォルダの扱い方
Ⅲ-4 集計表示の仕方
Ⅲ-5 HTML出力
Ⅲ-6 式と組込み関数
Ⅲ-7 アクセス制御
Ⅲ-8 操作ログ
Ⅲ-9 ライセンスの設定
Ⅳ PowerFolderの仕様Ⅲ-2 表の扱い方
Ⅲ-3 フォルダの扱い方
Ⅲ-4 集計表示の仕方
Ⅲ-5 HTML出力
Ⅲ-6 式と組込み関数
Ⅲ-7 アクセス制御
Ⅲ-8 操作ログ
Ⅲ-9 ライセンスの設定
■ Ⅱ-1 「探す」ことと「整理・分類」すること
「探す」、「整理・分類」することのモデルに図書館システムがあります。図書館には、本を読みに来る人、借りに来る人、返しに来る人がいます。
一方、図書館の人は、新刊の本や返却された本を「整理・分類」して所定の本棚に置きます。
【探す】
大量の本がある本棚から直接目的の本を探すことは容易ではありません。
図書館システムは、カードやコンピュータシステムによる検索により目的の本が「どの本棚」の「何段目」にあるかを知った上で、自分で本棚へ探しに行くか、 係の人に書庫で探してもらいます。
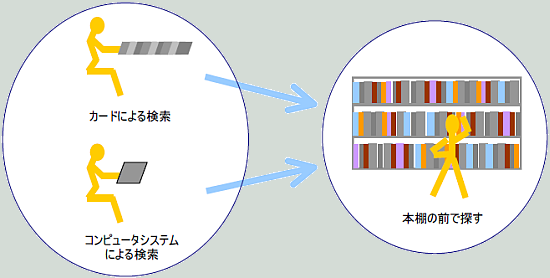 |
【本を探す手順】
① カードやコンピュータシステムで検索する。
カードの場合は、1枚ずつ内容を読みながら探します。
コンピュータシステムでは、ある程度のキーワードを入力すれば、候補が表示されその中から探し
ます。
② 本棚の前で探す。
目的が特定の1冊であれば、これで帰ることができます。
目的が本そのもではなく、「これこれについて調べる」という目的の場合は、本棚の前で適当な本を探します。
目的が本そのもではなく、「これこれについて調べる」という目的の場合は、本棚の前で適当な本を探します。
【整理・分類する】
前述の「本を探す手順」の①、②でそれぞれ探し易いように整理・分類をしておきます。
①の場合は、本そのものではなく本に関わる情報を整理・分類します。
例えば、カード方式の場合、著作者で整理してあるカード群からでも、タイトルで整理してあるカード群からでも同じ目的の本を探すことができます。
実態ではない情報の整理・分類ですから2枚のカードから同一の本を探すことができます。
②の場合は、実態としての本の整理・分類です。
ある本がそれの仲間と同じ場所にあるように整理・分類しなければなりません。
しかも、新刊で仲間は増えていき本棚の占有スペースも増えていきますので、絶えず整理・分類してあまり閲覧のない本は、地下の書庫に移動したりしなければなりません。
更に、保管場所が変われば、カード、コンピュータシステムの保管場所の情報を更新しなければなりません。
図書館では、「探す」ことと「整理・分類」することが上手にできるように工夫されています。
PowerFolderの内部的なデータの管理の仕方は図書館システムに似ています。
前述の①に相当する検索の工夫と、②に相当する管理するデータの格納方法の工夫がなされており、これらが一体となって機能するようになっております。
①に相当する工夫は、フォルダに管理するデータを検索する仕組みを組み込みました。
3種類のフォルダを組み合わせることで、ユーザが自分にあったデータの整理・分類ができます。
フォルダについての詳細は、「Ⅲ-3 フォルダの扱い方」で説明しています。
条件設定は、「Ⅲ-3 フォルダの扱い方」の【条件フォルダの作成】で説明します。
このとき、ユーザは、②に相当する実データの格納について何も意識する必要がありません。
フォルダについての詳細は、「Ⅲ-3 フォルダの扱い方」で説明しています。
条件設定は、「Ⅲ-3 フォルダの扱い方」の【条件フォルダの作成】で説明します。
このとき、ユーザは、②に相当する実データの格納について何も意識する必要がありません。
②に相当する工夫は、実データが頻繁に追加、更新されてもディスクの中で効率良く格納できるように工夫しました。
32bitマシンのファイルシステムでは、1ファイル2GBの制約があります。
PoweFolderでは、論理的に52GBの空間を物理的に2GBのファイルに分割して効率良く管理しております。
PoweFolderでは、論理的に52GBの空間を物理的に2GBのファイルに分割して効率良く管理しております。
「探す」ということと「整理・分類」するというこの両面からコンピュータ内部のデータ管理とユーザインターフェースを考えてPowerFolderのデータ管理の仕組みができております。
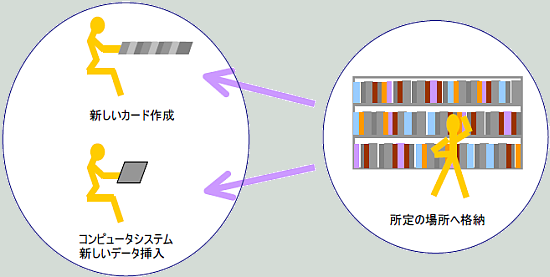
【新刊を登録する】
新刊が入荷した場合を考えてみます。
予め本棚は分類されていて新刊が収まる本棚とその位置はだいたい決まっています。
カードやコンピュータシステムへ新規のカードを作ったり、データを挿入して検索できるようにします。
 |
PowerFolderの考え方を上の図書館モデルと対比すると下のようになります。
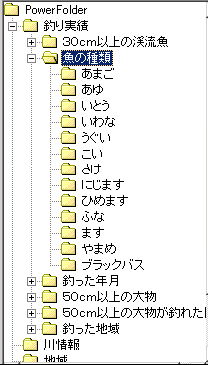 | 左は、表「釣り実績の」データの「魚の種類」で列挙したフォルダが表示されています。 新たに「うなぎ」を釣ったとします。 データ登録前は、「うなぎ」というフォルダはどこにもありません。 「うなぎ」は初めて釣られた魚です。 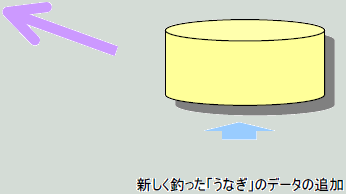 |
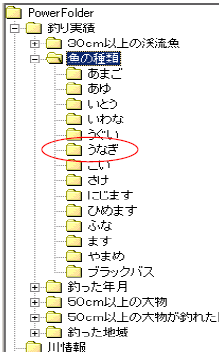 | 新しく釣った「うなぎ」のデータを追加するだけで、フォルダ「魚の種類」を開くと、新たにフォルダ「うなぎ」が自動的に作成されていて、フォルダ「うなぎ」を開くと新しく追加したデータの内容が表示されます。 新たなデータを追加した時 フォルダの条件に合致すれば、直ちにそのフォルダの中に新たに登録したデータも実在するかのように見えます。 更に、新たなデータの内容により列挙されるべき新たなフォルダも自動作成されます。 |
このように、PowerFolderは、グラフィカルなユーザインターフェースとデータベースを上手に使い、実世界の「探す」ことと「整理・分類」することをコンピュータの世界で新しいフォルダ概念で分かり易く実現しております。